Descriptive part
This subject allows me to deepen my knowledge of clustering algorithms using python and artificial intelligence.
The algorithms are mainly based on the sklearn library.
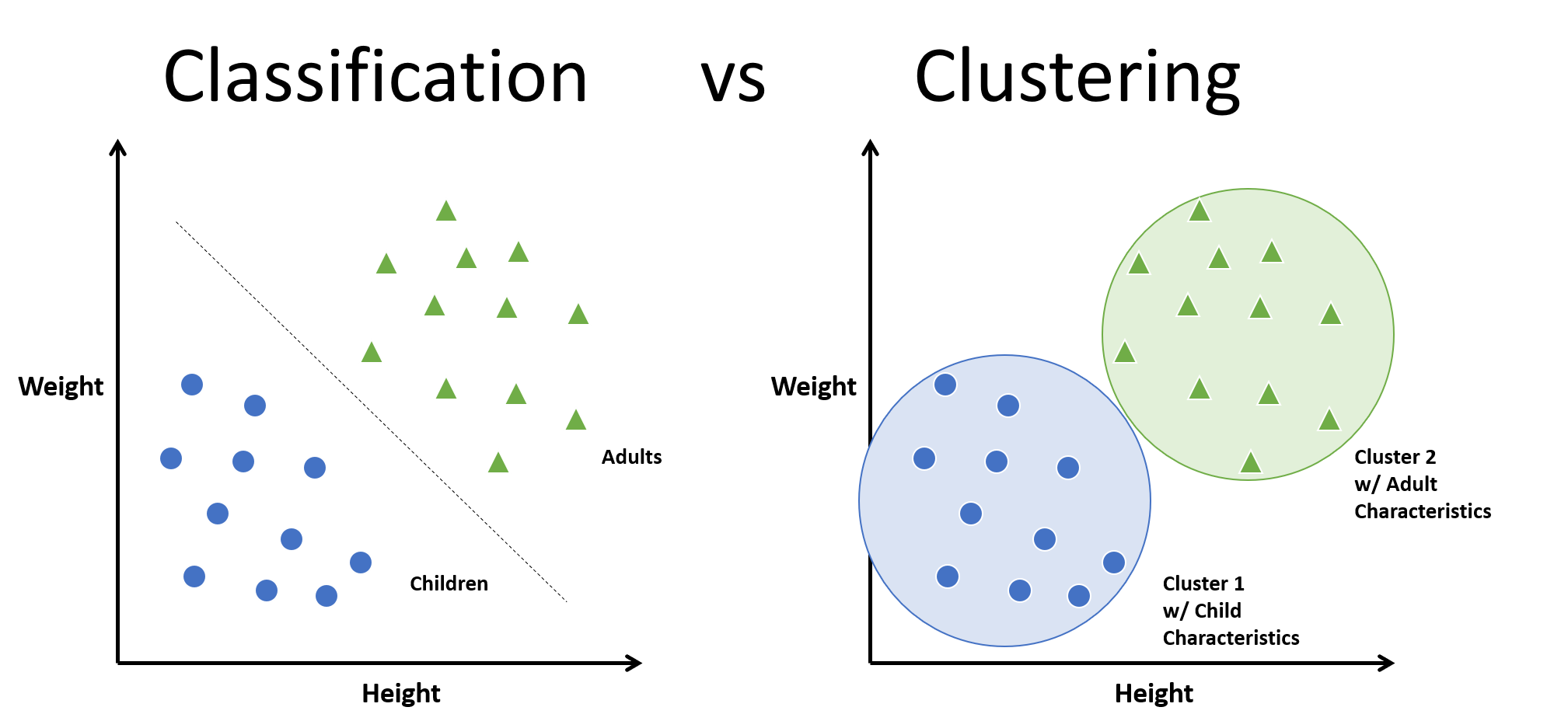
Here we can see the difference between the classification method and the clustering method.
In general, in classification, you have a set of predefined classes and you want to know to which class a new object belongs.
Clustering tries to group a set of objects and look if there is any relationship between the objects.
In the context of machine learning, classification is supervised learning and clustering is unsupervised learning.
Everything is organized in the form of 3 practical works: the use of k-means, agglomerative clustering and DBSCAN.For more information, I invite you to download and read my report here.
TP N°1:
K-Means
K-Means relies on the variance to define its clusters, so a cluster groups points with equal variance. It assumes that the clusters are of Convex form. The method requires to know the number of clusters K in advance and corresponds to several fields of use.
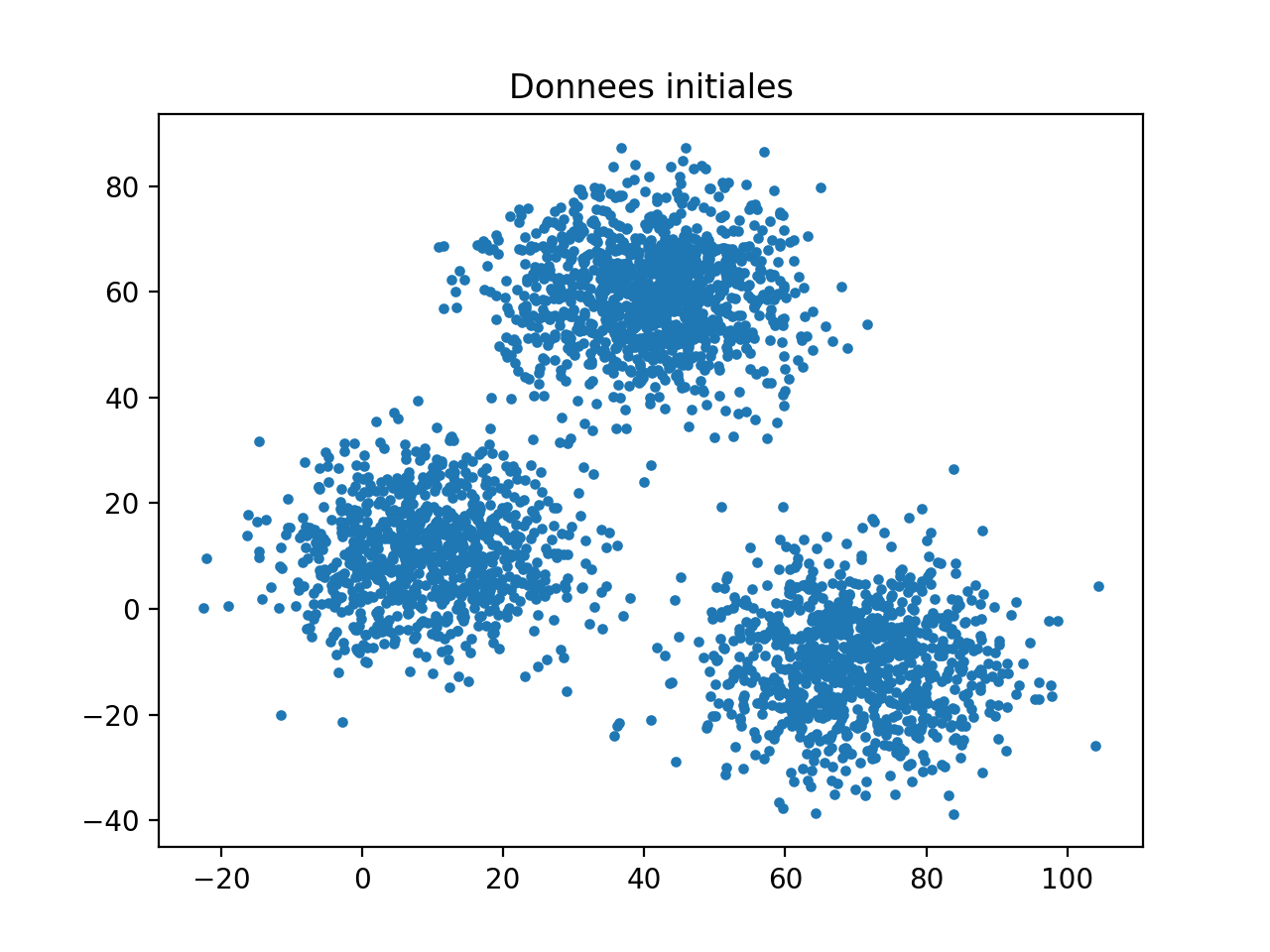
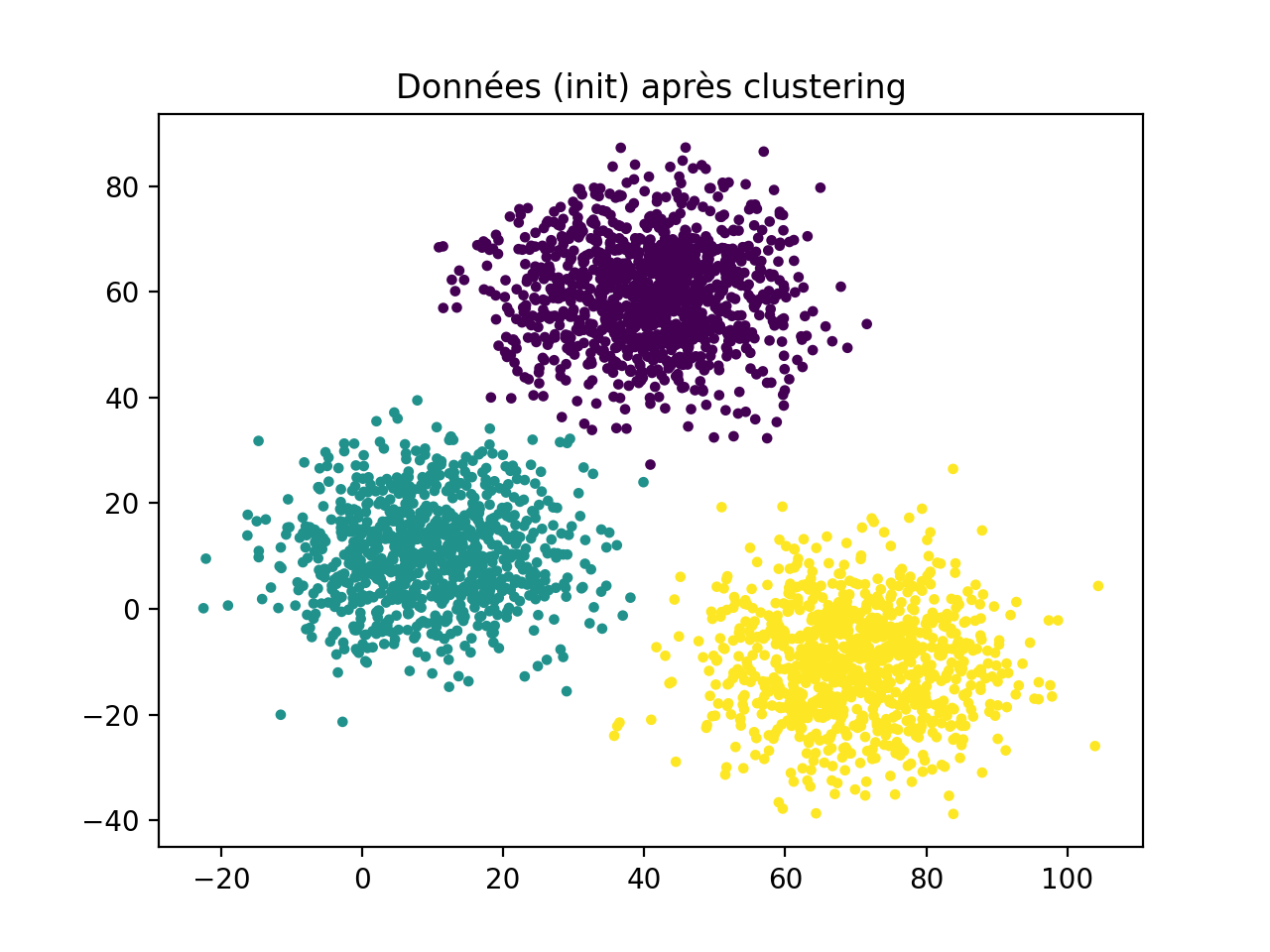
Initial data without standardisation
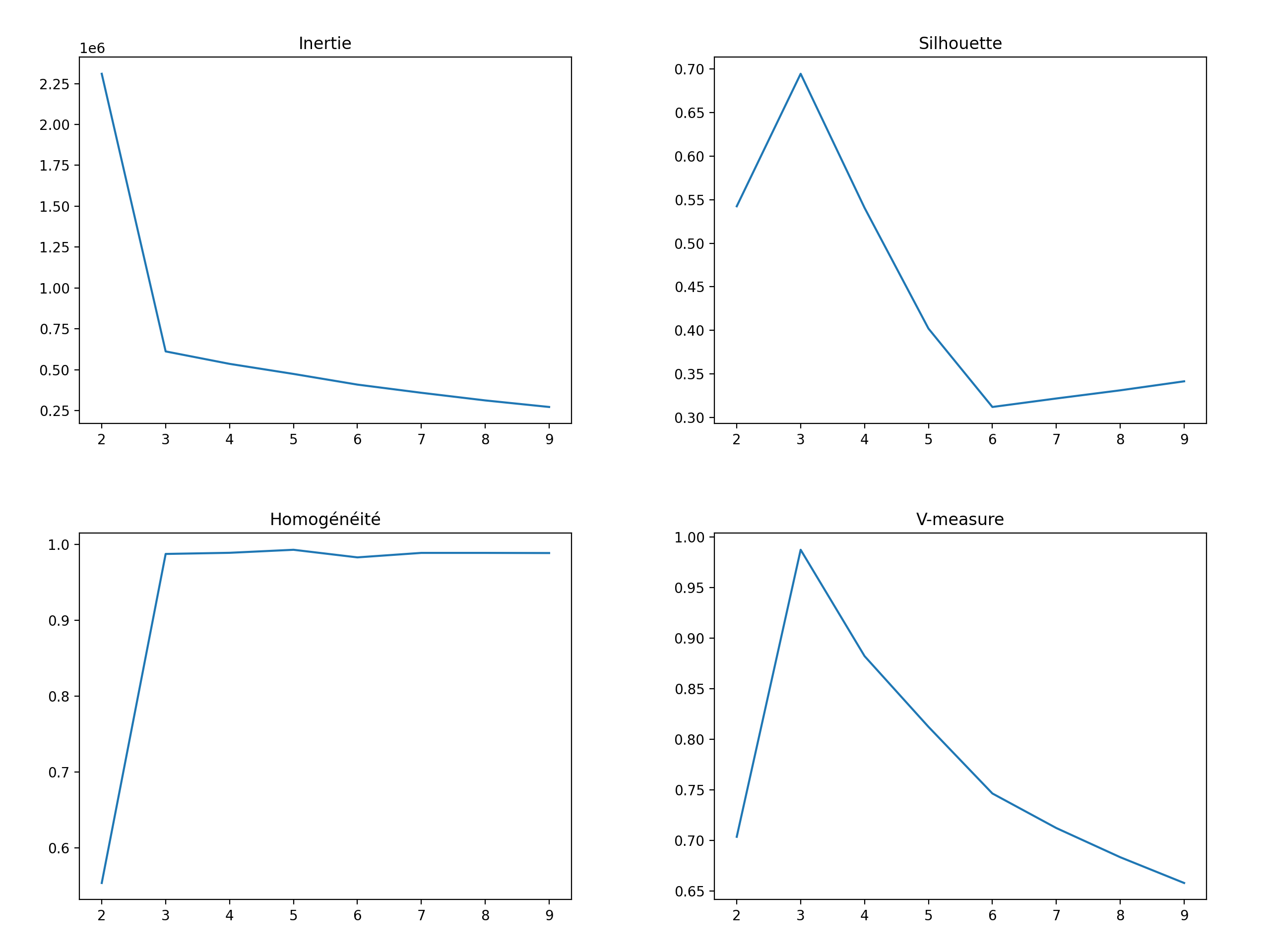
To measure the performance of algorithms we use metrics. Here, I chose to use the inertia, the silhouette coefficient, the homogeneity coefficient and the v-measure. For inertia and homogeneity, we look for the k that corresponds to the elbow on the graph. For the silhouette and the v-measure, we look for the k that corresponds to the maximum.
Results on this dataset. The determination of k is determined automatically using the metrics.
The agglomerative clustering is the most common type of hierarchical clustering used to group objects in clusters based on their similarity. The algorithm starts by treating each object as a singleton cluster. Next, pairs of clusters are successively merged until all clusters have been merged into one big cluster containing all objects. The result is a tree-based representation of the objects, named dendrogram.
DBSCAN is a well-known unsupervised clustering algorithm. DBSCAN iterates over the points of the dataset. For each of the points it analyzes, it constructs the set of points reachable by density from this point: it computes the epsilon-neighborhood of this point, then, if this neighborhood contains more than n_min points, the epsilon-neighborhoods of each of them, and so on, until the cluster cannot be enlarged anymore. If the point considered is not an interior point, i.e. it does not have enough neighbors, it will be labeled as noise. This allows DBSCAN to be robust to outliers since this mechanism isolates them.
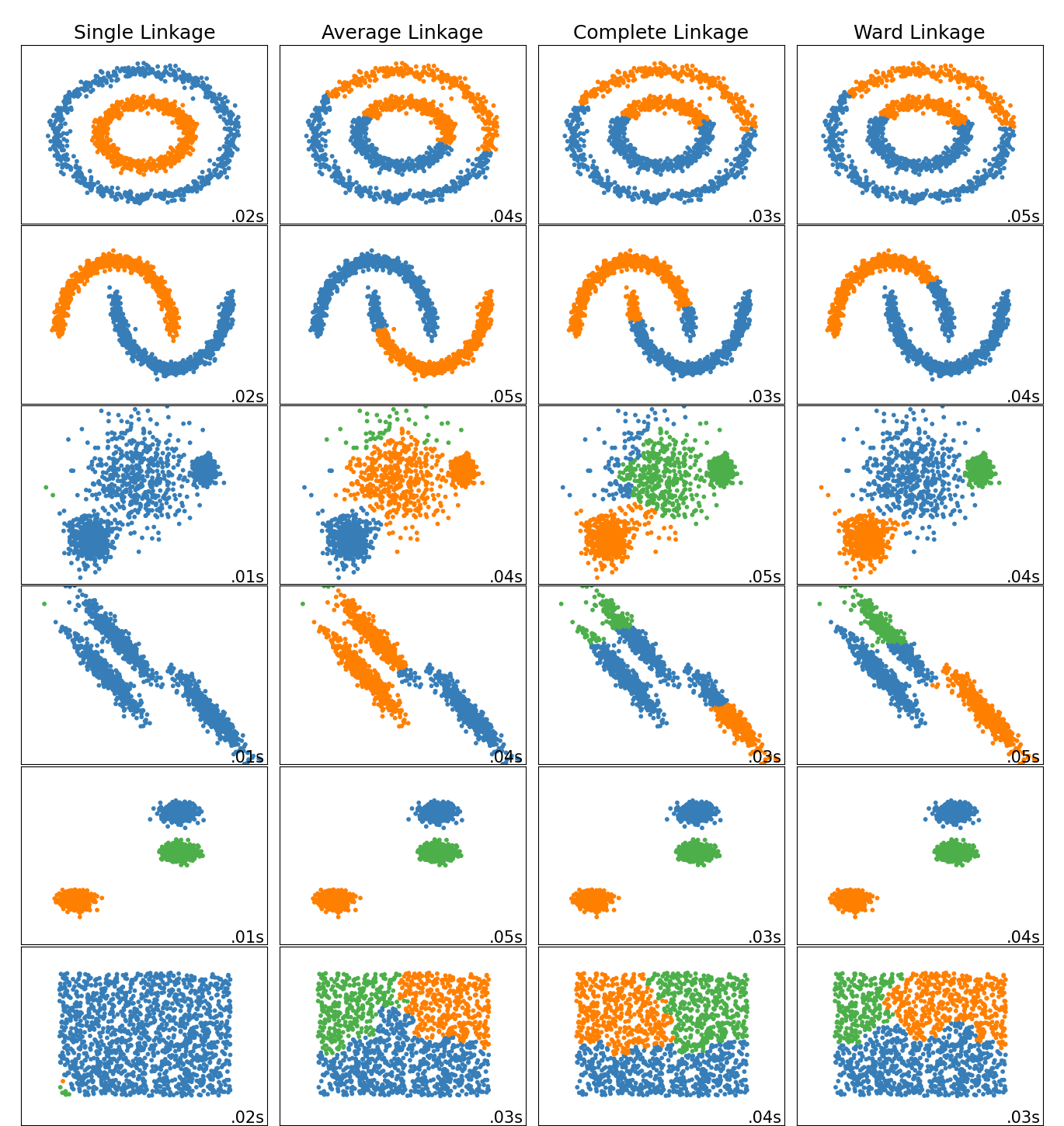
Linkage parameters and its effects according to the dataset type:
- Single: the distance between two clusters is the distance between the two closest points
- Ward: minimizes the variance between two clusters to calculate the distance between them
- Average : considers that the distance between two clusters is the average distance between the points of the clusters
- Complete : contrary to single, the distance between two clusters is the distance between the two farthest points
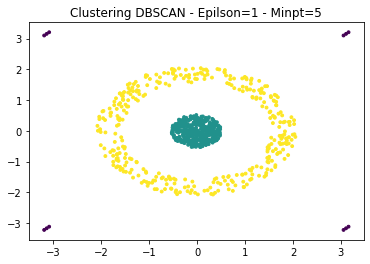
Here is an example of the DBSCAN algorithm with the parameters that seem to fit. The purple points are excluded from the clusters and considered as anomalies.
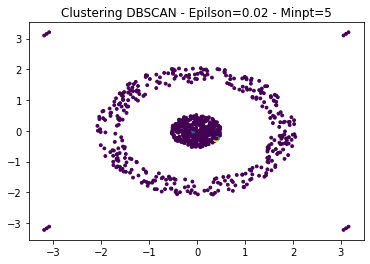
Example of DBSCAN with wrong parameters
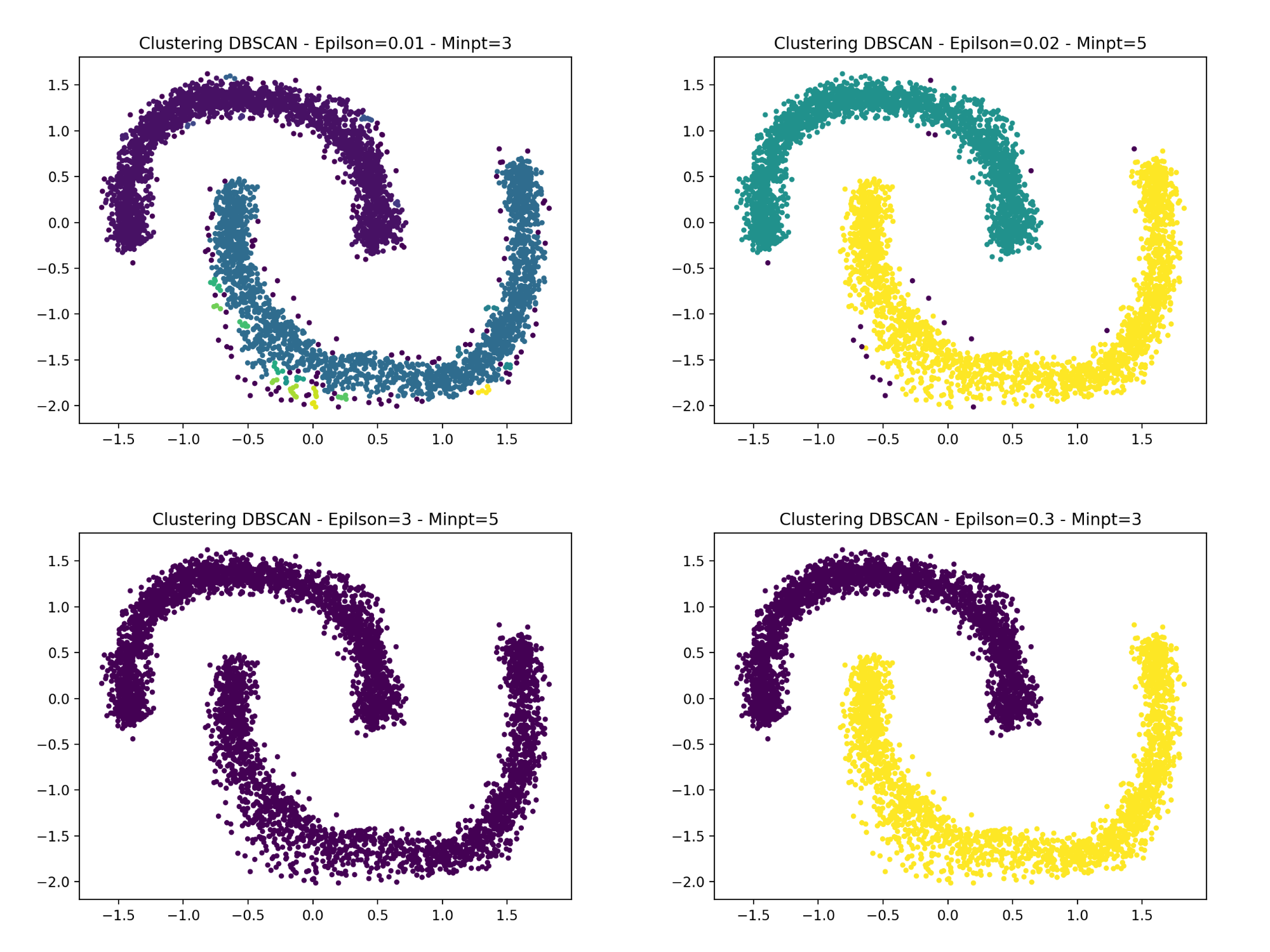
Influence of the parameters on the final results
TP N°2:
Agglomerative clustering & DBScan
Tp N°3:
Real world dataset
This part gathers the three methods seen previously and applies them on a real dataset with 33 parameters. Here, all hyper-parameters are determined automatically.
.png?h=56a7b4d5e5ad555bc35192bdb730943d)
We apply a dimension reduction to go from 33 parameters to only 2 using the PCA. The parameters are previously normalized with the MinMax method. The data are then identified according to their geographical positions.
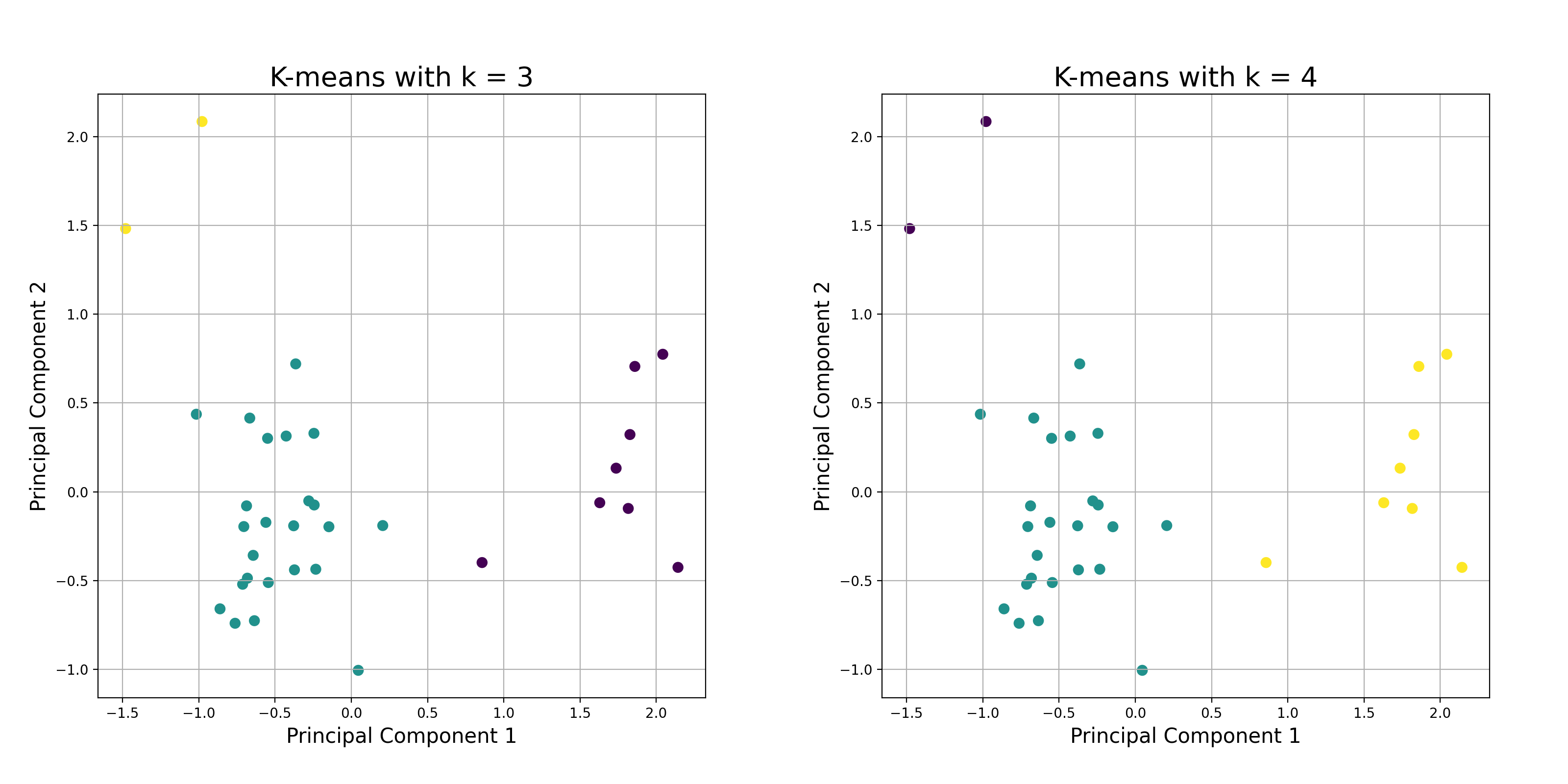
The K-Means algorithm gives us the following result with k automatically determined (here, k = 3) and k fixed (k = 4).
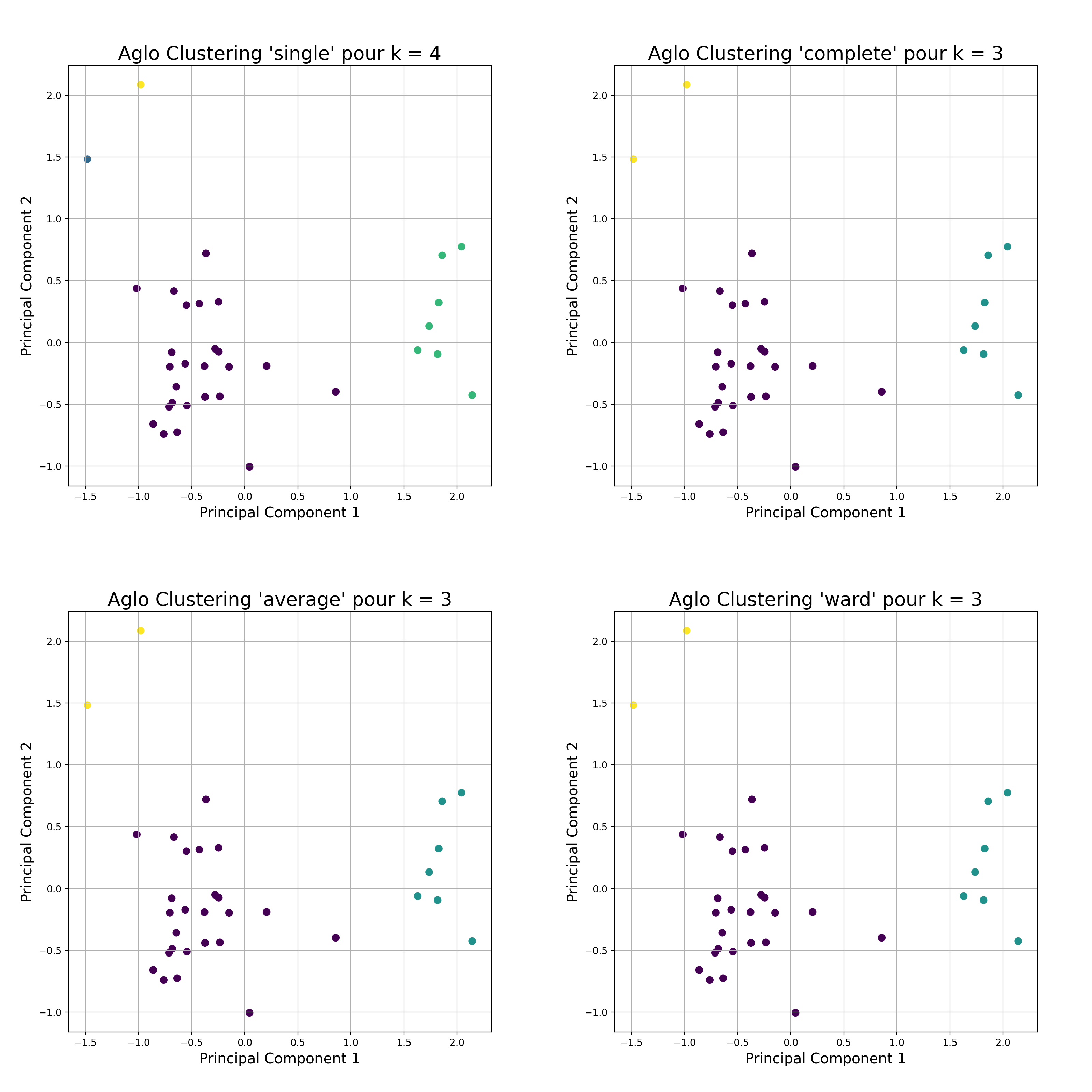
The agglomerative clustering algorithm gives us the following result always with k determined automatically and for the four possible types of linkage.
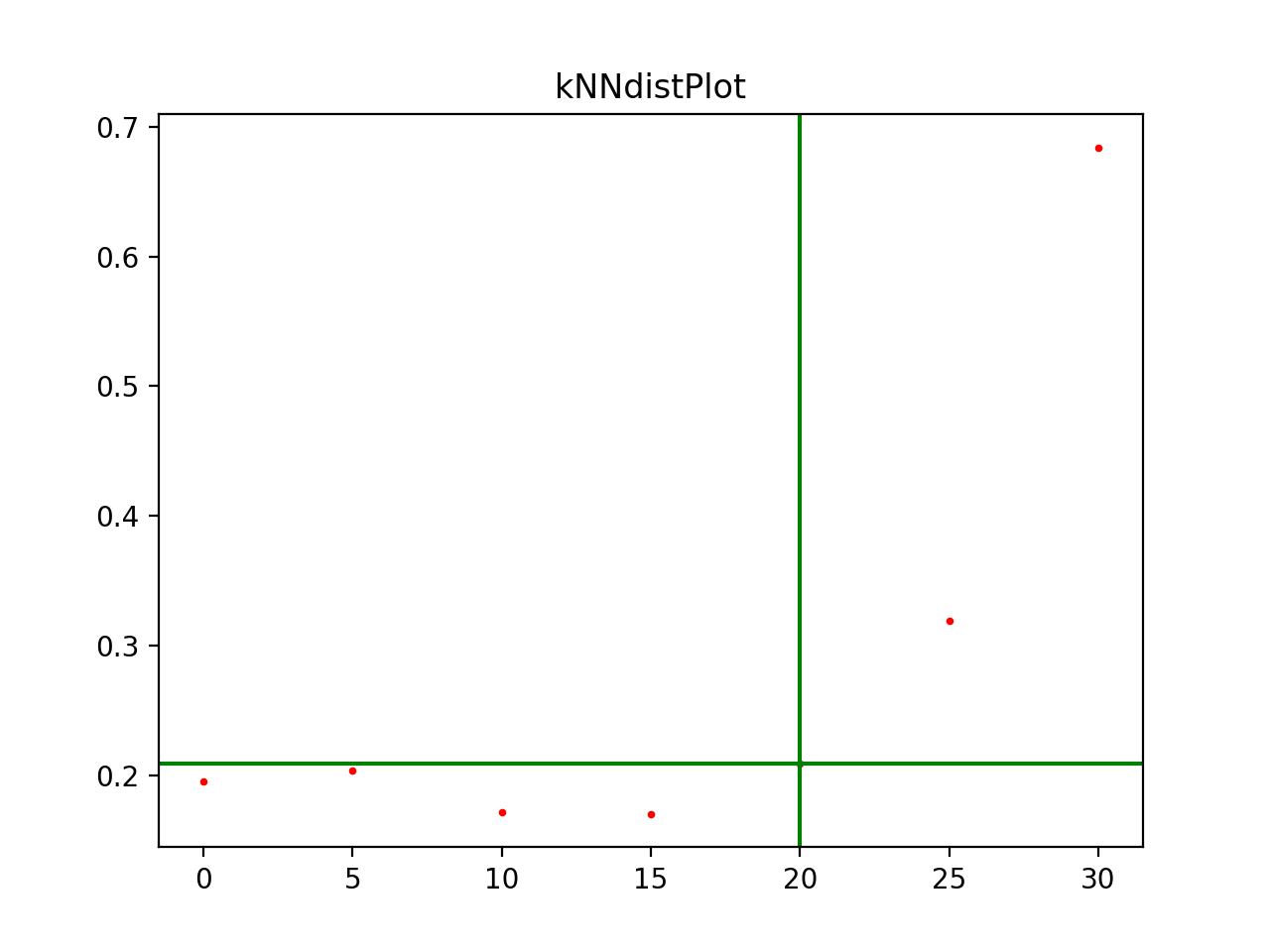
For the DBSCAN algorithm, we can no longer use the usual metrics. Instead, we use the k-nearest neighbors (KNN) algorithm and a function to determine the best epsilon for the DBSCAN that lies at the intersection of the green lines.
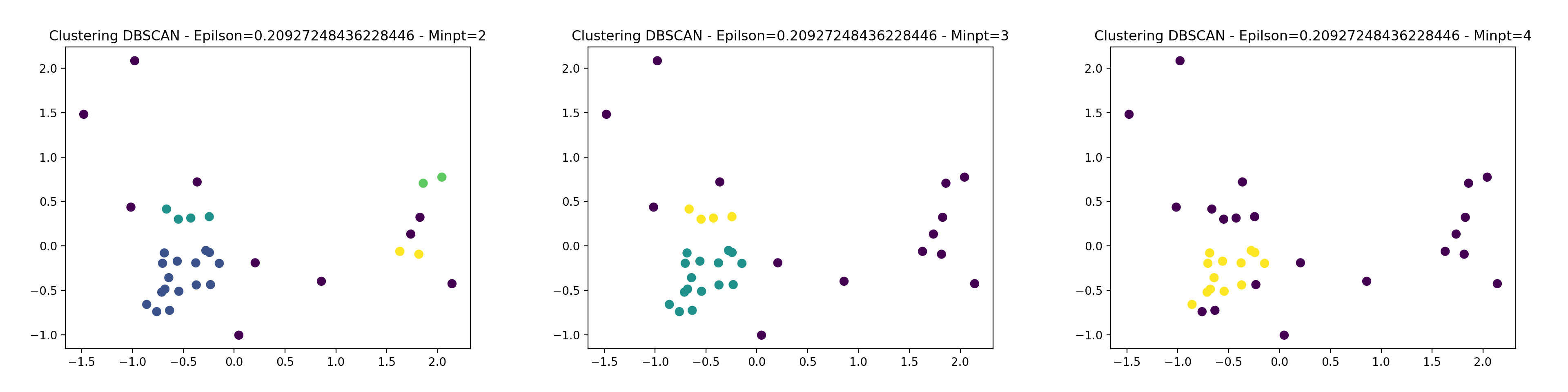
The DBSCAN algorithm gives the following results with epsilon determined automatically and with the minimum point set at 2 and 3. Beyond 4, the results are very similar.